카프카 컨슈머 알아보기
카프카 컨슈머는 하나의 컨슈머 그룹에 속해 실행되며 카프카 브로커의 토픽 파티션은 컨슈머 그룹 내 하나의 컨슈머에 할당된다.
카프카 컨슈머 구성요소


| 구성 요소 | 역할 |
|---|---|
| ConsumerNetworkClient | Kafka Consumer의 모든 Network 통신을 담당 |
| SubscriptionState | Topic / Partition / Offset 정보를 저장하고 관리하는 담당 |
| ConsumerCoordinator | Consumer Reblance / Offset 초기화 및 커밋을 담당 |
| HeartBeatThread | 백그라운드에서 동작하며, Consumer가 살아있다고 Coordinator 에게 알려주는 담당 |
| Fetcher | 브로커로부터 데이터를 가져오는 담당 |
ConsumerNetworkClient / Fetcher

동작 과정
- ConsumerNetworkClient는 비동기로 계속 브로커의 메시지를 가져와서 Linked Queue에 저장
- Fetcher는 Linked Queue에서 데이터를 읽음
- Linked Queue에 데이터가 있을 경우 Fetcher는 데이터를 가져오고 반환 하며 poll() 수행 완료
- Linked Queue에 데이터가 없을 경우 Fetcher가 ConsumerNetworkClient에게 데이터를 브로커로 부터 가져올 것을 요청
- ConsumerNetworkClient는 Broker에 메시지 요청하여 poll 수행()
Fetcher
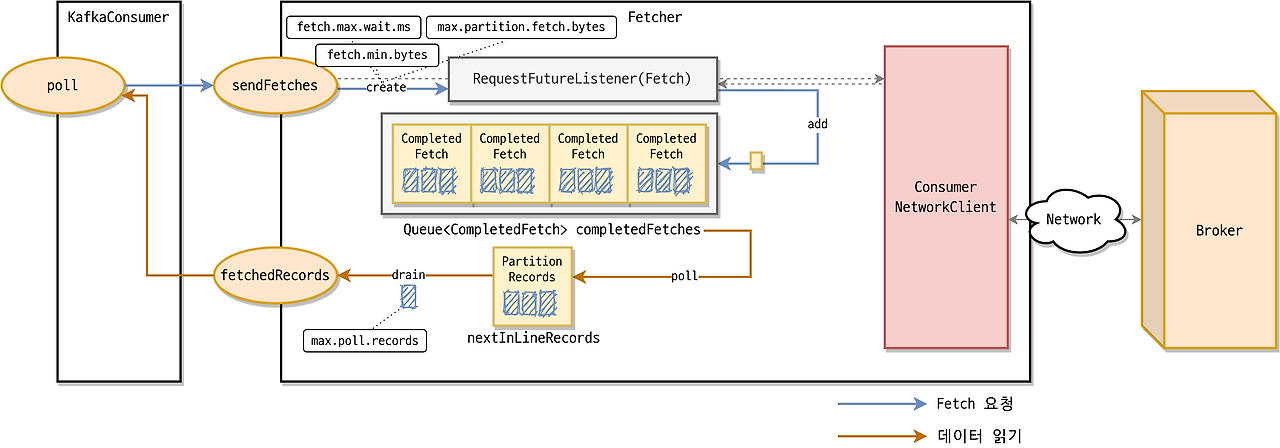
Consumer Fetcher 설정 파라미터
| 파라미터 | 기본값 | 설명 |
|---|---|---|
| fetch.min.bytes | 1 | Kafka Consumer 가 조회할 수 있는 최소한의 Record 의 크기, Fetcher가 record들을 읽어들이는 최소 bytes. 브로커는 지정된 fetch.min.bytes 이상의 새로운 메시지가 쌓일때 까지 전송을 하지 않음. |
| fetch.max.wait.ms | 500ms | 브로커에 fetch.min.bytes 이상의 메시지가 쌓일 때까지 최대 대기 시간. |
| fetch.max.bytes | 50MB | Fetcher가 한번에 가져올 수 있는 최대 데이터 bytes. |
| max.partition.fetch.bytes | 1MB | Fetcher가 파티션별 한번에 최대로 가져올 수 있는 bytes. Broker 가 Consumer 에게 제공할 수 있는 파티션별 데이터의 Bytes 제한. |
| max.poll.records | 500 | Fetcher가 한번에 가져올 수 있는 레코드 수. |
Consumer Fetcher 설정 파라미터 동작 방식
- 가장 최신의 offset 데이터를 가져오고 있다면 fetch.min.bytes 만큼 가져오고 return 하고 fetch.min.bytes만큼 쌓이지 않는다면 fetch.max.wait.ms 만큼 기다린 후 return
- 가져와야할 과거 데이터가 많을 경우 max.partition.fetch.bytes로 배치 크기 설정
- 그렇지 않을 경우 fetch.min.bytes로 배치 크기 설정
- 과거 offset 데이터를 가져 온다면 최대 max.partition.fetch.bytes 만큼 파티션에서 읽은 뒤 반환
- max.partition.feth.bytes에 도달하지 못하여도 가장 최신의 offset에 도달하면 반환
- 토픽에 파티션이 많아도 가져오는 데이터량은 fetch.max.bytes로 제한
- Fetcher가 Linked Queue에서 가져오는 레코드의 개수는 max.poll.records로 제한
Heartbeat Thread
카프카 컨슈머 클라이언트는 HeartBeat Thread 를 통해서 주기적으로 브로커의 Group Coordinator에 컨슈머의 상태를 전송한다. Group Coordinator는 카프카 브로커중 한대가 담당한다.
컨슈머 Hearbeat을 받아 컨슈머가 동작 중인지 확인하고 Heartbeat가 오지 않으면 컨슈머가 다운되었다고 판단해 컨슈머를 컨슈머 그룹에서 제외시킨 다음, 리밸런스를 컨슈머로 명령한다.
- Heartbeat Thread는 Background 에서 동작하며, Coordinator에게 컨슈머가 살아있음을 알린다.
- 이전에는 HeartBeatThread가 없어서 데이터 프로세싱 기반하는 것으로 Kafka consumer의 Health Check 를 함께 수행했는데 이 경우, 데이터 프로세싱이 길어지면 Consumer가 살았는지 죽었는지 즉각 확인할 수 없는 이슈 때문에 해결책으로 별도의 Thread 를 유지하게 되었다.
- 즉, 데이터를 프로세싱 하는 부분과 Consumer의 헬스 체크를 분리하였다. -> polling interval 과 heartbeat interval 을 분리
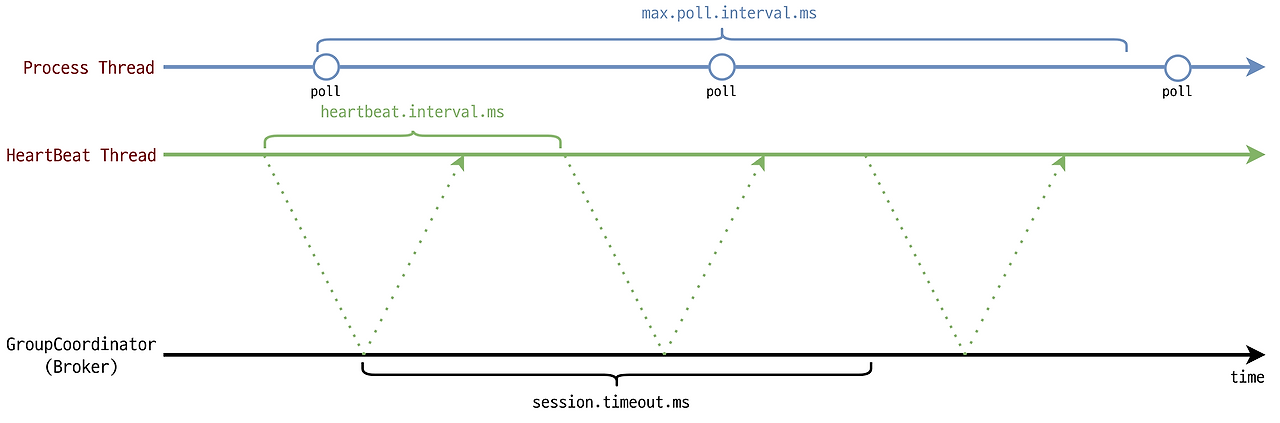
| 옵션 | 정책 |
|---|---|
| max.poll.interval.ms (default = 300000ms = 5분) | 이전 poll( )호출 후 다음 호출 poll( )까지 브로커가 기다리는 시간. 해당 시간 내에 poll이 호출되지 않으면 Group에서 제외된다.(rebalance 수행) HeartBeat 쓰레드가 poll 호출 간격을 측정하게 된다. |
| heartbeat.interval.ms (default = 3000ms = 3초) | 해당 주기 간격으로 HeartBeat를 Group Coordinator 로 전송한다. 일반적으로 session.timeout.ms 의 1/3 로 활용한다. |
| session.timeout.ms (default = 10000ms = 10초) | 해당 시간동안 HeartBeat이 도착하지 않으면 Group Coordinator 는 해당 Consumer를 Group 에서 제외한다.(rebalance 수행) |
- max.poll.interval.ms 제한이 있으므로, max.poll.records 값을 적절하게 조정하는 것이 필요하다.
- polling 한 데이터 프로세싱 과정(in Appication) 에서 로직 문제로 지연이 발생한다면 결국 poll.interval 이 늘어나게 된다. 즉, 보편적으로 record의 수에 따라 데이터 컨슈밍 과정에서 지연 시간이 늘어나게 될 것이므로 적절한 값을 설정할 필요가 있다.
- 혹, 컨슈머에서 메시지를 읽어서 처리하는 서비스 로직의 수행 시간을 줄일 수 없다면 max.poll.interval.ms 를 늘리거나 파티션을 추가하는 등의 방법을 고려해야 한다.
리밸런싱
리밸런싱은 컨슈머 그룹 내에서 컨슈머 추가나 삭제(Heartbeat을 받지 못한 경우)와 같은 변경이 생길 때 파티션과 컨슈머의 조합을 변경하는 과정이다. topic에 변경(파티션 수 증감 / 구독하는 토픽 변경)이 발생해도 리밸런싱이 수행될 수 있다.
브로커의 그룹 코디네이터 Group Coordinator가 컨슈머들에게 파티션을 재할당하는 리밸런싱을 지시한다.
리밸런싱 과정
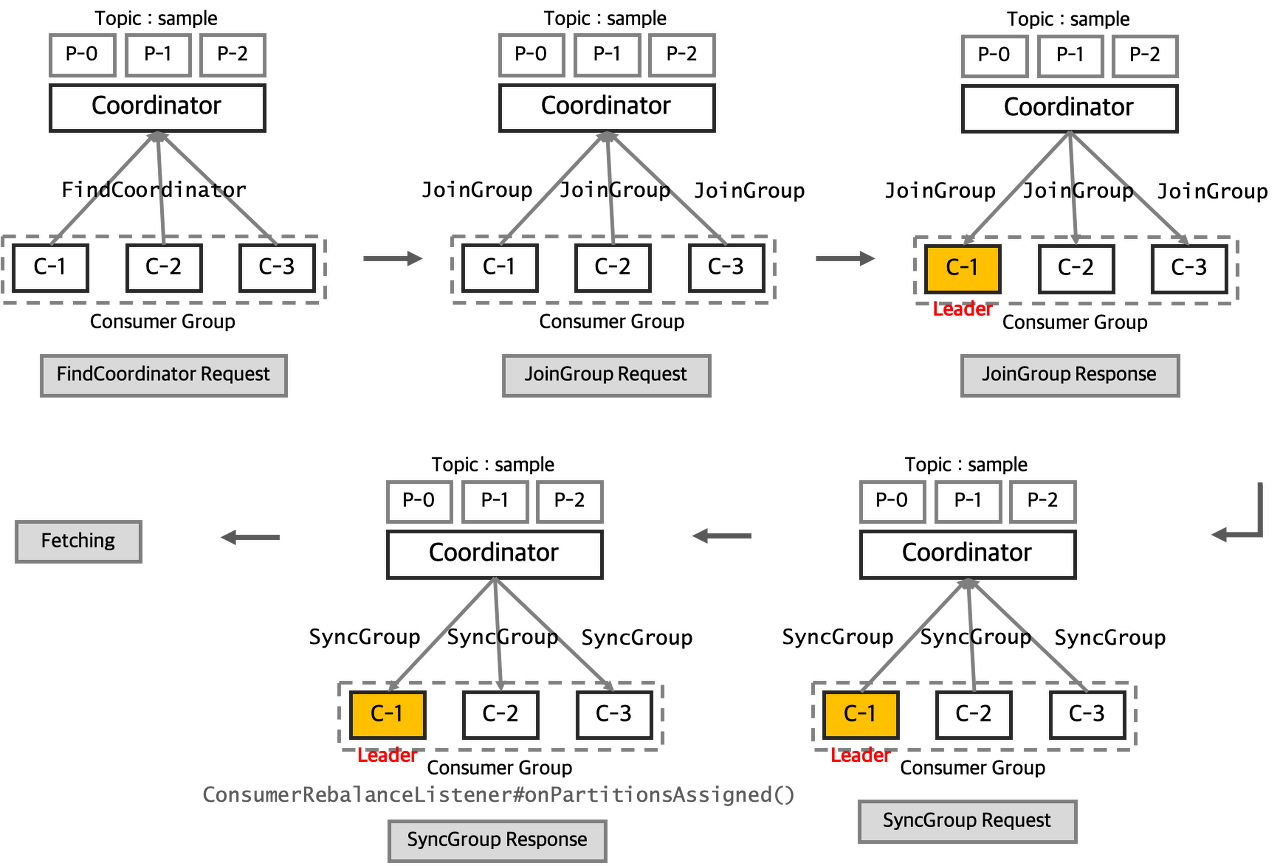
- FindCoordinator Request: Consumer Coordinator 가 Join Group 요청을 보낼 Group Coordinator를 찾는다.
- 컨슈머 그룹 내의 컨슈머가 브로커에 최초 접속을 요청하면 Group Coordinator가 생성된다.
- 리밸런스 수행시, 그룹 코디네이터는 컨슈머 그룹 내의 모든 컨슈머들의 파티션 소유권을 박탈한 뒤, 컨슈머들의 JoinGroup 요청을 일정 시간 기다린다다.
- JoinGroup Request: Group의 정보와 Subscription 정보를 수집하고, 리더를 선출한다.
- 동일 group.id 의 여러 컨슈머가 브로커의 Group Coordinator로 접속한다. 그 중 가장 빨리 Group에 Join 요청을 한 컨슈머를 컨슈머 그룹내의 리더 컨슈머로 지정한다.
- SyncGroup Request: 리더가 그룹내에 Consumer에게 Partition을 할당하고, Group Coordinator에게 해당 정보를 보낸다.
- 리더 컨슈머는 파티션 할당전략에 따라 컨슈머들에게 파티션 할당한다.
- 정보 전달 성공을 공유한 뒤 개별 컨슈머들은 할당된 파티션에서 메시지 읽어온다.
Kafka가 Rebalancing 되는 과정 중에서는 모든 Consuming( Data Fetching ) 작업이 멈춰지는 STW(Stop The World) 현상이 발생하게 된다.
Consumer Gruop Status

컨슈머 그룹은 Group Meta Data에 컨슈머 그룹의 상태를 저장한다. 상태는 아래 3가지와 같다.
- Empty : 컨슈머 그룹은 존재하지만 컨슈머는 없는 상태
- Rebalance : Rebalance 수행 상태
- Stable : Rebalance가 종료되고 안정적으로 컨슈머 운영 중인 상태
Consumer Static Group Membership
컨슈머 그룹 내의 컨슈머들에게 고정된 IP를 부여한다. 이를 통해 컨슈머 그룹에 최초 조인 시 각 컨슈머들에 할당된 파티션을 그대로 유지하고, 컨슈머가 shutdown되어도 session.timeout.ms 내에 재기동 되면 리밸런스가 수행되지 않고 기존 파티션이 재할당 되도록 한다.
컨슈머 그룹 내에서 리밸런스가 수행되면 모든 컨슈머들이 데이터를 소비하지 못하고 Consumer LAG 이 길어지게 되는데 Consumer 스태틱 그룹 멤버쉽으로 Consumer Restart 에서 불필요한 리밸런스가 발생하지 않도록 한다.
참고) Consumer LAG
프로듀서가 레코드 데이터를 produce하는 속도가 컨슈머가 가져가는 속도보다 빠른 경우 발생하는 토픽의 가장 최신 오프셋(LOG-END-OFFSET)과 컨슈머가 가져간 데이터의 오프셋(CURRENT-OFFSET) 간의 차이를 kafka consumer lag이라 부른다.
Consumer Rebalancing Protocol
Eager 모드
Rebalance 수행시 모든 컨슈머들의 파티션 할당을 취소하고, 새롭게 파티션을 할당하고 다시 메시지를 읽는다.
모든 컨슈머가 Rebalance 되는 동안 잠시 메시지를 읽지 않는 시간으로 인해 Lag가 상대적으로 크게 발생할 가능성 있다.
더하여 리밸런싱 이후에는 컨슈머가 이전에 가졌던 파티션을 반드시 다시 가질 수 있다는 보장을 할 수 없다.
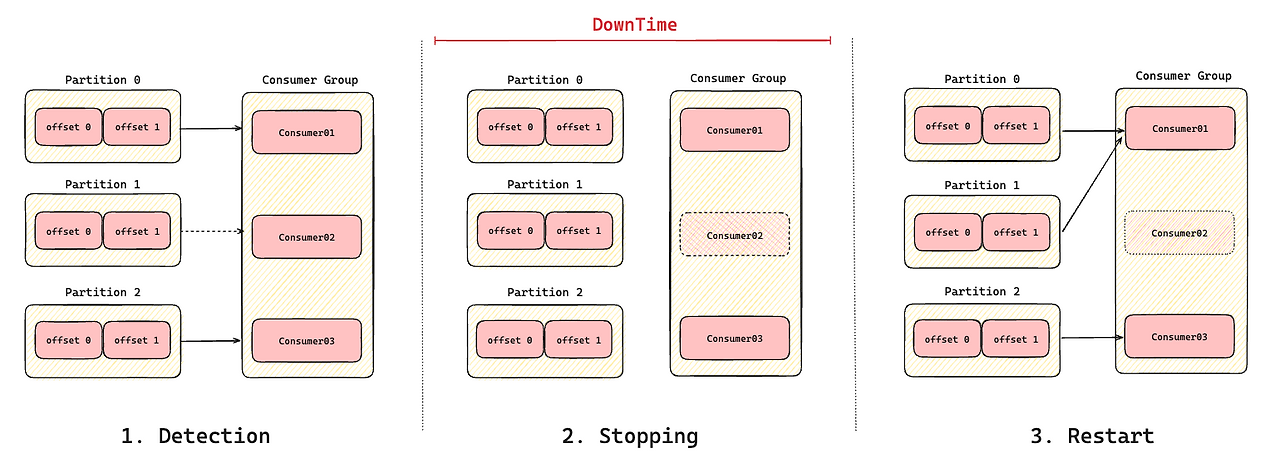
- Detection 단계에서 consumer02 의 장애를 감지하면,
- Stopping 단계에서 컨슈머에게 할당된 모든 파티션을 제거한다. 이후 모든 컨슈머에게 할당된 파티션이 없으므로 컨슈머의 다운타임이 시작된다.(STW)
- Restart 단계에서 구독한 파티션이 컨슈머들에게 재할당된다. 이 순간부터 컨슈머들은 각자 재할당받은 파티션에서 메시지를 컨슘하기 시작한다.
Cooperative 모드
Apache Kafka 2.4 버전부터 도입된 진보된 형태의 리밸런싱 방식으로 Rebalance 수행 시 컨슈머들의 모든 파티션 할당을 취소하지 않고 대상이 되는 컨슈머들에 대해서 파티션에 따라 점진적으로(Incremental) 컨슈머를 할당하면서 Rebalance를 수행한다.
많은 컨슈머를 가지는 컨슈머 그룹 내에서 Rebalance 시간이 오래 걸리는 경우에 활용하여 효율을 높일 수 있다.
Eager 방식과 달리 전체가 중단되지 않기 때문에 효율적일 수 있지만, 파티션 할당이 안정적인 상태가 될 때 까지 몇 번의 반복 작업이 필요할 수 있다는 점을 유의해야 한다.
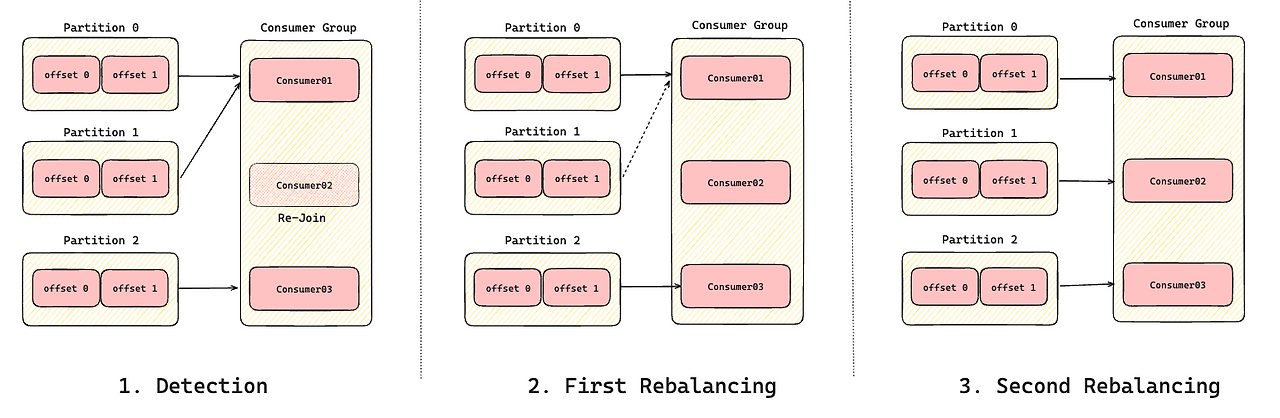
- Detection 단계 - 컨슈머 그룹에 Consumer02 가 합류하며 리밸런싱이 트리거 된다. 그룹 코디네이터는 해당 정보를 조합해 컨슈머 그룹의 리더에게 전송한다.
- First Rebalancing - 컨슈머 그룹의 리더는 현재 컨슈머가 소유한 파티션 정보를 활용해, 제외할 파티션 정보를 담은 새로운 파티션 할당 정보를 컨슈머 그룹 멤버들에게 전달한다.
- 새로운 파티션 할당 정보를 받은 컨슈머 그룹 멤버들은 필요없는 파티션을 골라 제외한다.
- 이전의 파티션 할당 정보와 새로운 파티션 할당 정보가 동일한 파티션들에 대해서는 어떤 작업도 수행할 필요가 없다.
- Second Rebalancing - 제외한 파티션 할당을 위해 컨슈머들에 다시 합류 요청을 전송한다. 이 때 두 번재 리밸런싱이 트리거 된다. 컨슈머 그룹의 리더는 제외된 파티션을 적절한 컨슈머에게 할당한다.
Consumer 파티션 할당 전략
카프카 Consumer에 파티션을 균등하게 할당하고 데이터 처리 및 리밸런싱의 효율성 극대화하기 위해 4개의 파티션 할당 전략 유형을 제공한다.
Round Robin 할당 전략

Round Robin 전략은 토픽들의 파티션을 순차적으로 Consumer에 할당하므로 파티션 매핑이 Consumer별로 비교적 균일하다.
Rebalancing 시에도 토픽들의 파티션과 Consumer들을 균등하게 매핑하므로, Rebalance 이전의 파티션과 Consumer들의 매핑이 변경되기 쉽다.
Range 할당 전략 (기본 전략)
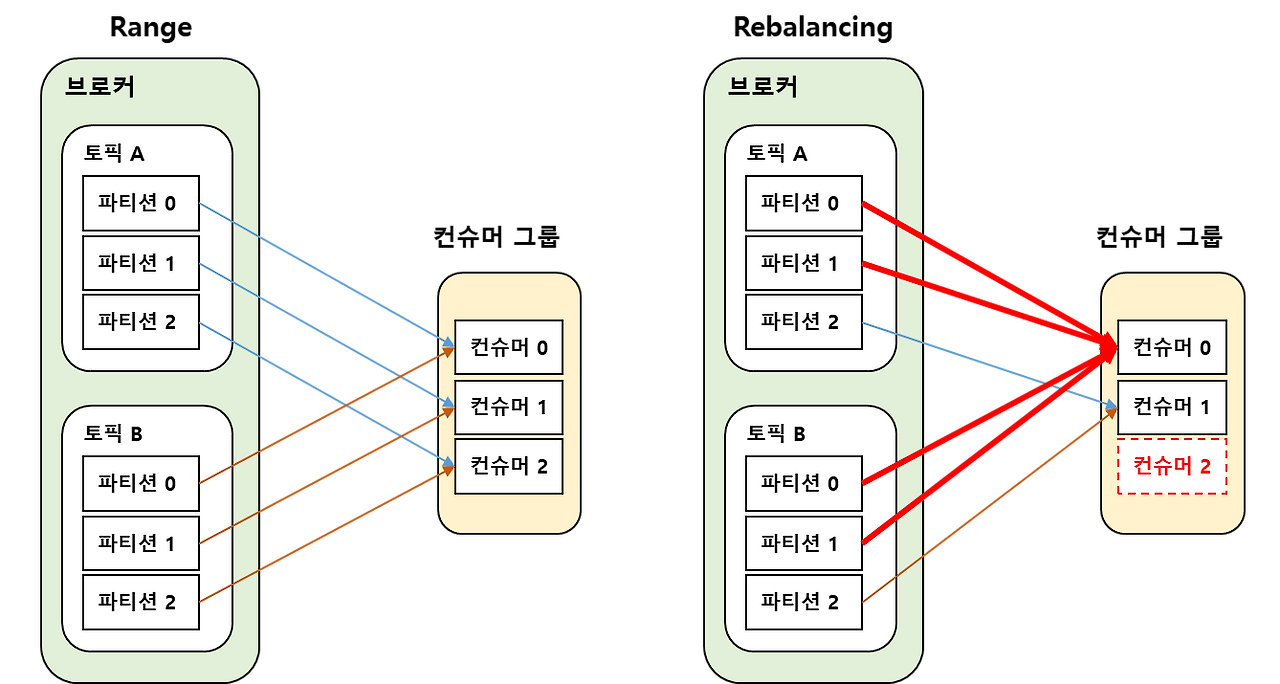
Apache Kafka 2.3 버전까지 디폴트로 설정된 파티션 할당 전략이다.
Range 전략은 서로 다른 토픽들의 동일한 파티션들을 같은 Consumer로 할당한다. 레인지 파티션 할당 전략은 다음 순서로 진행된다.
- 구독 중인 토픽의 파티션과 컨슈머를 순서대로 나열한다.
- 각 컨슈머가 받아야 할 파티션 수를 결정하는데, 이는 해당 토픽의 전체 파티션 수를 컨슈머 그룹의 총 컨슈머 수로 나눈 값이다.
- 만약 컨슈머 수와 파티션 수가 정확히 일치하면 모든 컨슈머는 파티션을 균등하게 할당 받는다.
- 그러나 파티션 수가 컨슈머 수로 균등하게 나누어지지 않으면, 앞 순서의 컨슈머들이 추가로 파티션을 할당 받는다. 이는 파티션이 한쪽으로 몰릴 수 있는 문제점이 있다.
레인지 파티션 할당 전략은 Rebalancing 시에도 서로 다른 토픽에서 동일한 키값을 가지는 파티션들은 같은 Consumer에서 처리 할 수 있도록 유도한다.
Sticky 할당 전략
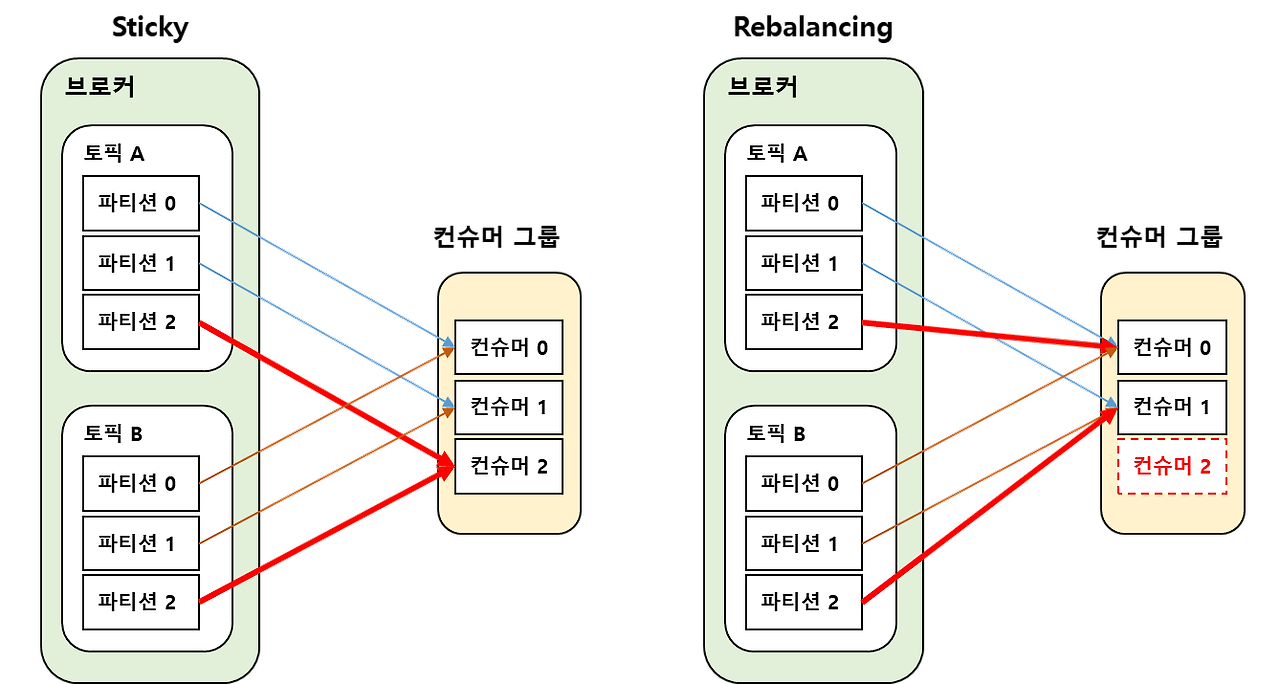
Rebalancing 시 기존 토픽들의 파티션과 Consumer 매핑은 최대한 유지하고 재할당되어야 하는 파티션들만 다른 Consumer들에 재할당한다.
하지만 모든 Consumer들의 파티션이 일제히 취소되는 Eager Protocol 기반에서 동작한다.
Cooperative Sticky 할당 전략
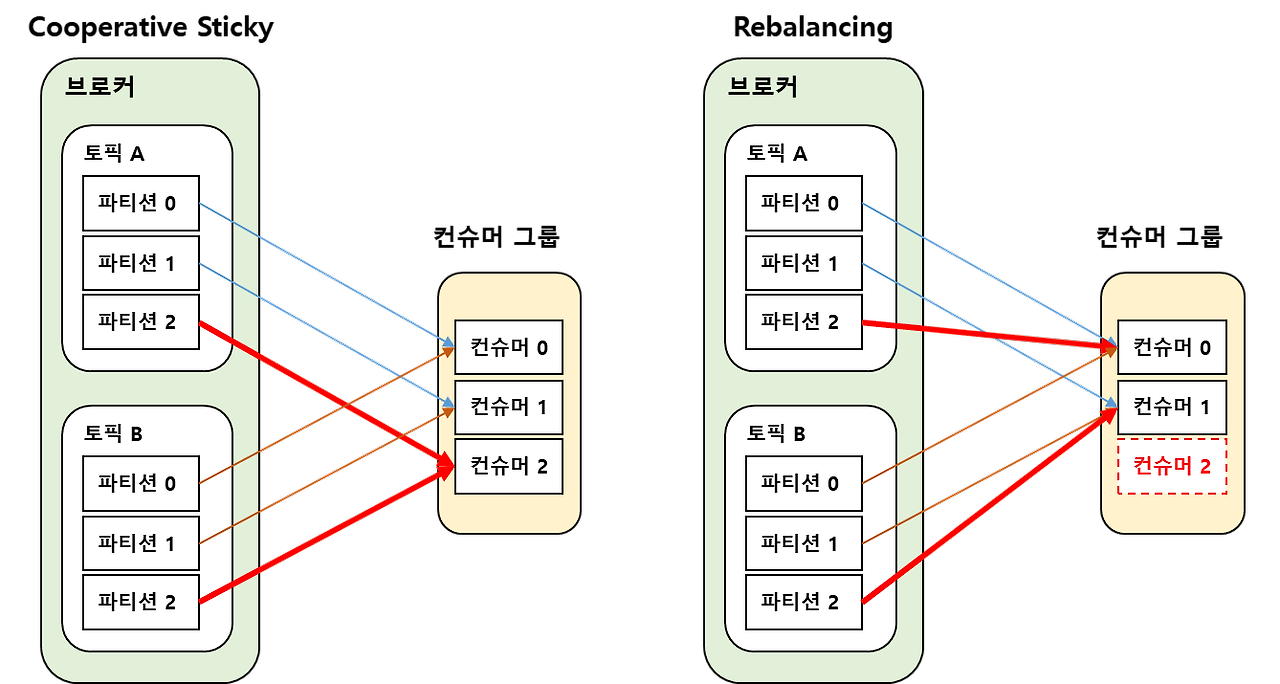
Kafka version 2.4 부터 디폴트 파티션 할당 전략으로 스티키 파티션 할당 전략과 결과적으로 동일하지만 컨슈머 그룹 내부의 리밸런싱 동작은 한층 더 고도화 됐다.
Rebalancing 시 기존 토픽들의 파티션과 Consumer 매핑은 최대한 유지하고 재할당되어야 하는 파티션들만 다른 Consumer들에 재할당한다.
모든 매핑을 다 취소하지 않고 기존 매핑을 그대로 유지한채 재할당되어야 할 파티션만 Consumer에 따라 순차적으로 Rebalance를 수행한다.
참고 자료
'Infra > Messaging' 카테고리의 다른 글
| Kafka Consumer 알아보기 2. (0) | 2025.06.10 |
|---|---|
| 카프카 프로듀서 Client(Java/Spring) (0) | 2025.06.03 |
| 카프카 메세지 전달 보장(Kafka Message Delivery Semantics) (1) | 2025.05.23 |
| 카프카와 래빗엠큐 비교해보기 (0) | 2025.05.20 |

